SpeedCurve is now part of the Embrace family! There are no changes to how you use our products. Our founder Mark shares what this means...
An update on the recent JavaScript error tracking outage

During a deployment at 08:00 pm on 7 May 2026 (UTC), SpeedCurve RUM JavaScript error tracking had an outage that lasted for 5 days, until 08:00 pm on 12 May. The outage caused the complete loss of JavaScript error details recorded by SpeedCurve's RUM script, lux.js. Total error count was recorded correctly, but the details of those errors were lost.
The speed of trust: How slow pages hurt your brand

Performance isn’t just a technical metric or a revenue lever. It’s a perception engine. Every delay subtly reshapes how users evaluate your credibility, professionalism, and trustworthiness. Once perception shifts, it’s difficult to reverse.

We’ve known for years that slow pages hurt conversion rates. They increase bounce. They reduce revenue. They drag down engagement.
But there’s another cost that’s harder to measure and potentially more damaging in the long term: Slow pages change how people feel about your brand.
How fast is fast enough? Rethinking web performance in pragmagical terms
In a world full of friction – slow lines, dropped calls, canceled flights – creating moments of digital flow can feel like a gift. "Fast enough" isn’t just about protecting conversion rates. It’s about creating experiences that preserve momentum, reduce friction, and feel almost invisible.

When it comes to web performance, how fast is fast enough?
It’s a question I’ve tried to answer in different ways over the years. But while preparing this talk for performance.now(), I decided to go back to first principles. I tried to look at the question with fresh eyes – to set aside the patterns I’ve accumulated after years of working in the performance space and ask myself: what does "fast" really mean?
The honest answer? It depends.
There are so many variables. Any attempt to reduce "fast enough" to a single number – 1.2 seconds, 2.5 seconds, 100 milliseconds – quickly falls apart. If you came here hoping for a universal threshold, I’m sorry to disappoint you.
Instead, I want to explore something more nuanced: what fast feels like and how we might bridge the gap between business pragmatism and user delight.
Because somewhere between those two lies what I like to call the "pragmagical".
2025 was a big year! Here are some highlights...
I say this every year, and every year I mean it: this has been a big year, for both SpeedCurve and the web performance community!

Some highlights:
- Broad browser support for important metrics like Largest Contentful Paint and Interaction to Next Paint
- Exciting new metrics and visualizations for measuring user happiness — as well as identifying the root causes of issues that lead to user UNhappiness
- Nuanced metrics for deeper diagnostics (especially digging into JavaScript issues that were previously elusive)
- Better performance budgets
- Easier for Shopify and Magento stores — as well as SPAs — to enjoy all the benefits of real user monitoring
Let's go!
NEW! A trickle of updates to your waterfall charts

Waterfall charts are the workhorse of any web performance enthusiast. SpeedCurve's interactive waterfall is one of the first components I designed and built more than a decade ago. I've just given our much-loved waterfall chart some team-inspired updates that you may find helpful in understanding how page construction affects important user experience metrics.
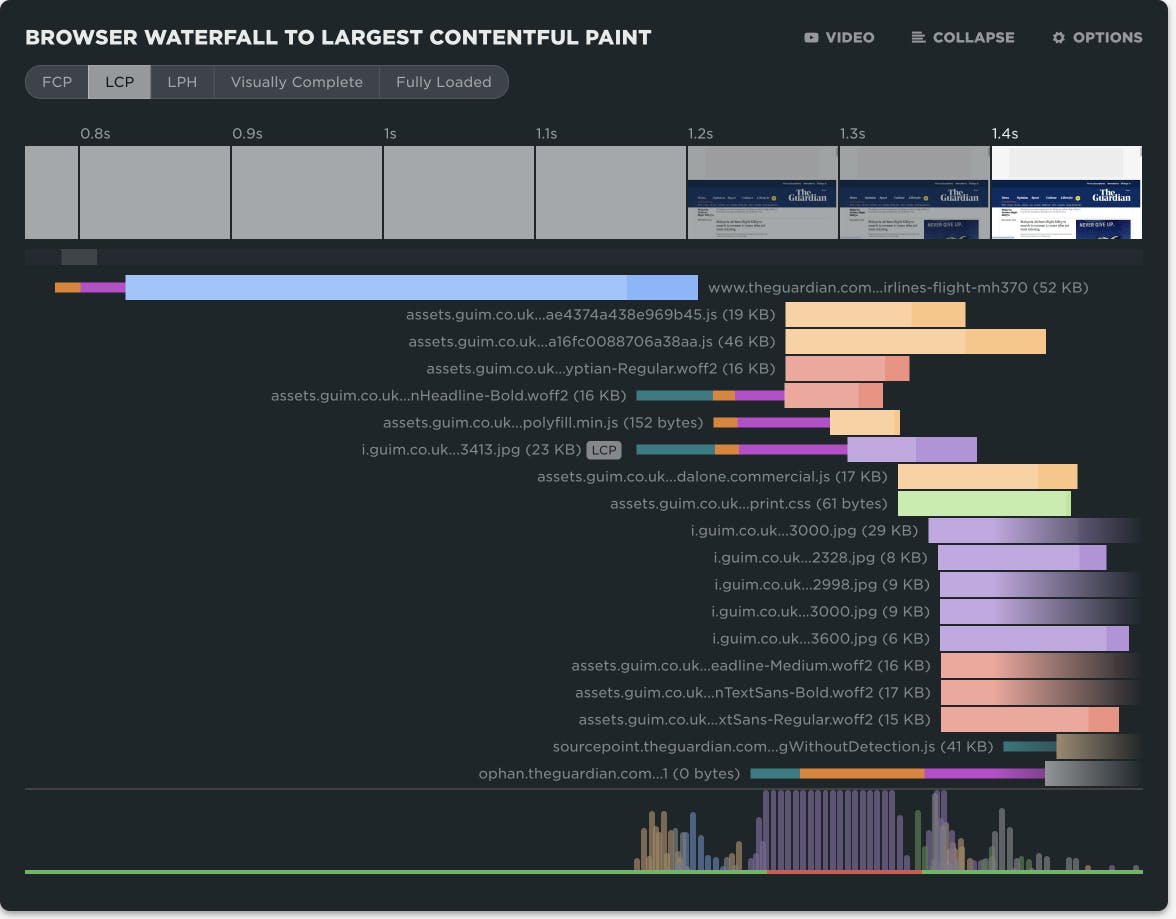
At SpeedCurve, we love incremental updates based on both external and internal user feedback. We dogfood our own products, and while consulting with customers, our in-house performance expert Andy Davies is often confronted by the gulf between a customers questions and how he might answer those questions using the data we collect and the visulizations we wrap around it.
It's not always easy. Making data visible doesn't automatically mean it's useful in answering questions about the intersection of web performance and user behaviour.
Three years ago Andy asked me for a feature in the waterfall chart. I added it straight away, and to this day Andy has never discovered or used the feature!
"Wait, you can do that?" ~ Andy
If Andy uses SpeedCurve everyday, knows it inside out, and still can't stumble across a three-year-old feature, that's not Andy's problem. That's a problem with complexity in the user interface and feature discoverability. It's a common problem as software matures and features get layered on top of each other. What started out simple and easy to explore becomes complex and hidden behind a myriad of options.
Today I'm taking a crack at removing some options in the waterfall to reduce complexity and choice while exposing better defaults.
I'm hoping Andy sees the changes this time around and it helps answer more of his questions...
NEW! A better way to quantify user happiness on your site
The goal of making websites faster is to make users happier. Since user happiness can't be measured directly, we launched the User Happiness metric more than six years ago. We've just released a fresh User Happiness update to reflect changes in web browsers and the overall web performance space!
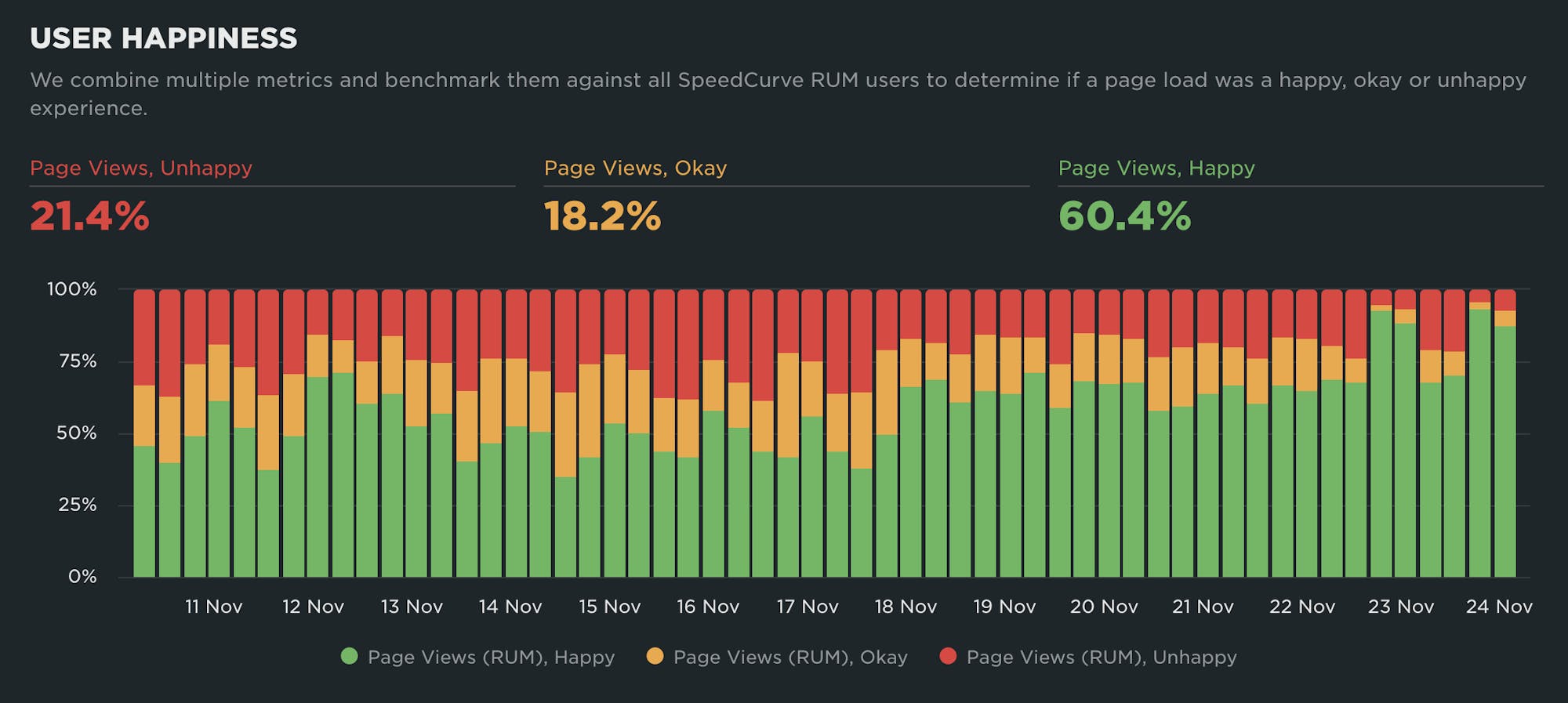
Back in October 2019, we released our User Happiness metric with the goal of quantifying how a user might have felt while loading a page.
User Happiness is an aggregated metric that combines important user experience signals, gathered with real user monitoring (RUM). To create the User Happiness algorithm, we picked metrics and thresholds that we felt reflected the overall user experience: pages that loaded slowly or lagged during interaction were more likely to make someone feel unhappy, whereas fast and snappy pages would keep users happy.
More than six years later, we've updated User Happiness to reflect changes in web browsers and the overall web performance space. Keep reading to learn more.
Performance is about people
Hey, you! 👋🏽 Yeah, you… the person who just clicked the link to get here and read this. Thanks for clicking, and thanks for giving this node a fraction of your attention.
Today, SpeedCurve joins Embrace. It’s going to be awesome and exciting. You can read all the details in the press release and Andrew's blog post or join us for a chat on Dec 9th.
I want to take this moment to remind you, and ourselves, why the web matters.
At its heart, the web is about humanity. It’s about how we choose to evolve ourselves. That’s why user experience, speed and curiosity are interlinked and matter so much.
I’ll keep it succinct: each moment is precious.
NEW! Heatmaps now available on Favorites Dashboards

We’re thrilled to announce that you can now add heatmaps to your Favorites (custom) dashboards in SpeedCurve!
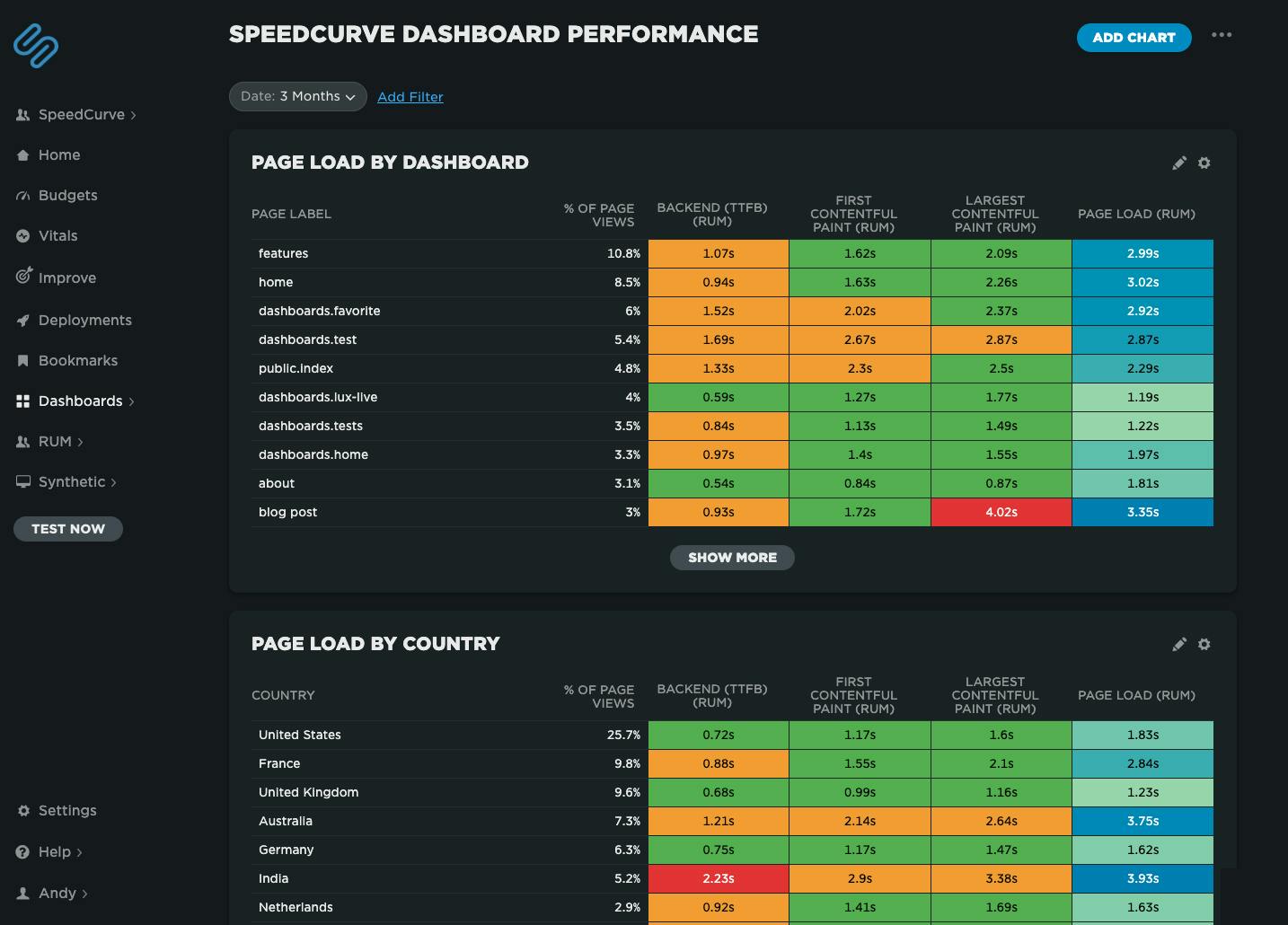 Speedcurve's own performance data for our dashboards. We've got some issues with our blog post page performance, possibly the huge images I've been uploading!
Speedcurve's own performance data for our dashboards. We've got some issues with our blog post page performance, possibly the huge images I've been uploading!
Heatmaps are a powerful way to get an instant overview of where performance issues are hiding across your site. They let you break down your performance metrics (including custom metrics) by different dimensions — including page label, browser, location, and device type — so you can easily spot anomalies and patterns in your web performance data.
For example, you might notice that a specific browser or region consistently loads your site more slowly, or that certain pages are lagging behind the rest. Heatmaps make it easy to visualize and spot those differences at a glance, helping you pinpoint where to focus your optimization efforts.
2025 Holiday Readiness Checklist (Page Speed Edition!)

Delivering a great user experience through the holiday season is a marathon, not a sprint. Here are 25 things you can do to make sure your site is fast and available every day, not just Black Friday.

Your design and development teams are working hard to attract users and turn browsers into buyers, with strategies like:
- High-resolution images and videos
- Geo-targeted campaigns and content
- Third-party tags for audience analytics and retargeting
However, all those strategies can take a toll on the speed and user experience of your pages – and each introduces the risk of introducing single points of failure (SPoFs).
Below we've curated 25 things you can do to keep your users happy throughout the holidays (and beyond). If you're scrambling to optimize your site before Black Friday, you still have time to implement some or all of these best practices. And if you're already close to being ready for your holiday code freeze, you can use this as a checklist to validate that you've ticked all the boxes on your performance to-do list.
NEW! A smarter way to spot performance issues
We’re excited to announce the launch of the Vitals Overview dashboard in SpeedCurve — your new starting point for exploring the performance of your site.
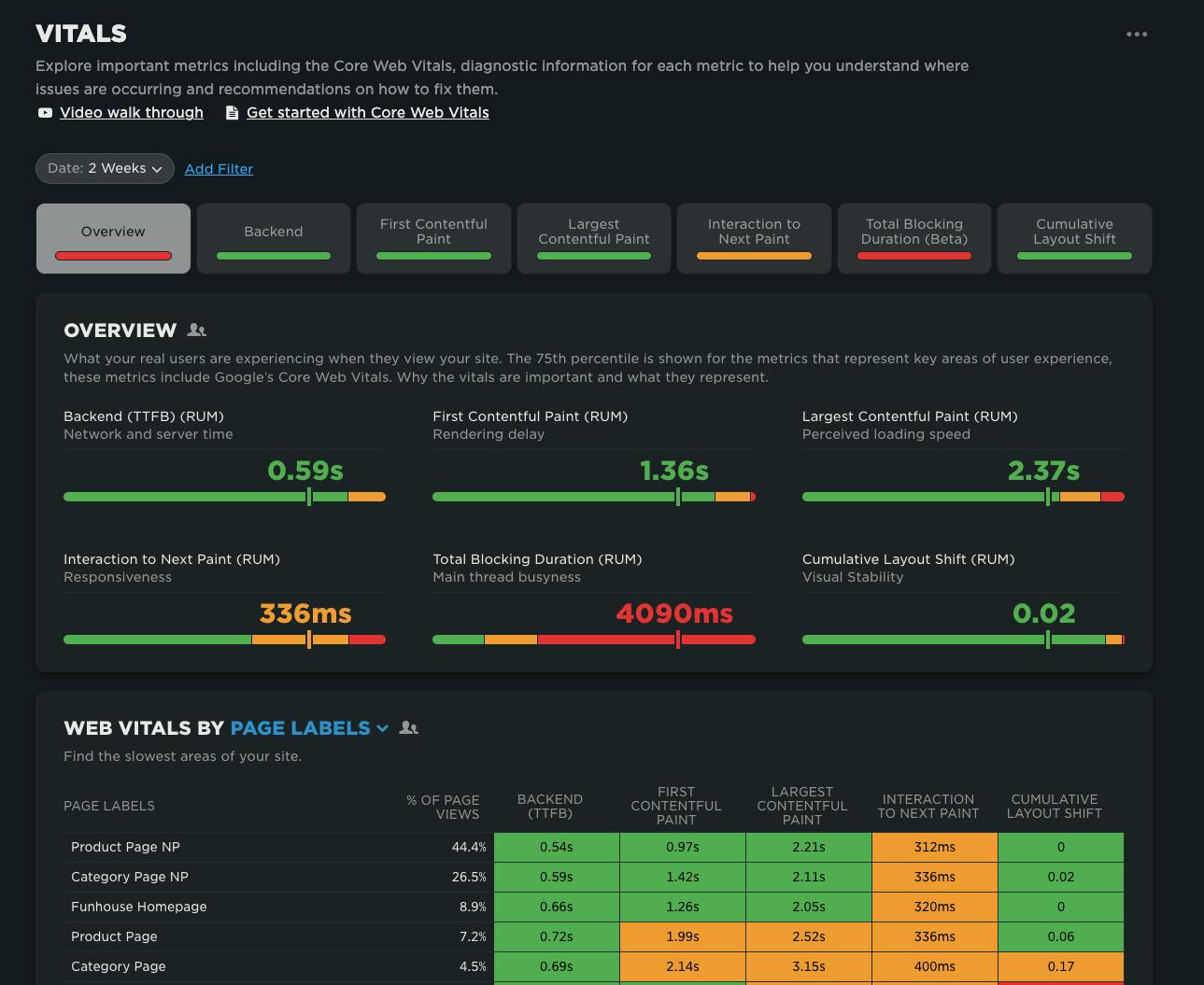
When it comes to improving web performance, the journey usually looks like this:
- Identify where the problems are
- Diagnose why they’re happening
- Fix the issues
- Validate that the fixes worked
Our new Vitals Overview dashboard is designed to make that critical first step — identifying performance issues — faster, clearer, and more actionable.
